Under active development. A stable version is expected in November 2026. Feedback is welcome by email or via GitHub issues.
4 Optimization for Machine Learning
4.1 Overview
Training a machine learning model is an optimization problem. The goal is to find the set of model parameters that minimizes a loss function, which measures how poorly the model fits the training data. Gradient-based methods are the standard tools for navigating the high-dimensional “loss landscape” to find this minimum. Stochastic-gradient methods trace back to stochastic approximation ideas such as Robbins and Monro (1951).
For econometricians, the key connection is that this is the same basic problem as nonlinear least squares or maximum likelihood estimation: choose parameters to minimize an objective function. What changes in machine learning is the scale of the parameter space, the non-convexity of the objective, and the reliance on iterative gradient-based updates.
This chapter explains how these optimization methods work at a general level. The next chapter then applies this machinery to feed-forward neural networks and backpropagation.
4.2 Roadmap
We begin with the basic intuition behind gradient descent.
We then compare batch, stochastic, and mini-batch updates, since this distinction is central in machine learning practice.
Next, we discuss the main weaknesses of vanilla gradient descent and motivate more advanced optimizers.
We then study Momentum, AdaGrad, RMSprop, and Adam.
Finally, we compare their behavior visually and summarize practical lessons for modern machine-learning estimation.
4.3 The Core Idea for Optimization: Gradient Descent
Imagine you are standing on a foggy mountain and want to get to the lowest valley. The simplest strategy is to look at the ground at your feet and take a step in the steepest downhill direction. You repeat this process until further steps no longer reduce the loss.
This is the core intuition behind Gradient Descent.
The “mountain” is the loss landscape.
Your “position” is the current set of model parameters, \(\boldsymbol \theta\).
The “steepest downhill direction” is the negative of the gradient of the loss function \(l\) with respect to the parameters, \(-\nabla_{\boldsymbol \theta} l(\boldsymbol \theta)\).
where \(\eta\) is the learning rate, a hyperparameter (a quantity chosen by the user rather than estimated from the data) that controls the size of the steps we take.
The main challenge is how to compute the gradient \(\nabla_{\boldsymbol \theta} L(\boldsymbol \theta)\). The way we use our training data to compute it leads to three main variants of gradient descent.
4.4 Notation
The notation below is used throughout the chapter:
Setup: Consider a supervised training dataset \(\mathcal{D}=\{(x_i,y_i)\}_{i=1}^N\) and parameter vectors \(\boldsymbol{\theta} \in \mathbb{R}^m\).
Key definitions:
\(\ell_i(\boldsymbol{\theta}) = \ell(y_i, \hat{y}_i)\): loss for individual sample \(i\)
\(L(\boldsymbol{\theta}) = \frac{1}{N}\sum_{i=1}^N \ell_i(\boldsymbol{\theta})\): average training loss
\(x_i\): predictors, \(y_i\): observed value, \(\hat{y}_i\): predicted/fitted value depending on \(\boldsymbol{\theta}\)
\(\mathcal{D} = \{(x_i,y_i): i = 1, \dots, N\}\): the complete training dataset
Notation Convention
For brevity, we write \(\hat{y}_i\) instead of \(\hat{y}_i(\boldsymbol{\theta})\), but remember that predictions always depend on the current parameters.
4.5 Batch, Stochastic, and Mini-Batch Gradient Descent
Batch Gradient Descent
In Batch Gradient Descent, we calculate the gradient of the loss function using the entire training dataset in one go. With learning rate \(\eta > 0\) and starting value \(\boldsymbol{\theta}^{(0)}\), the gradient for iteration \(t=1,\ldots,T\) is:
Pros: The gradient is the exact training-set gradient, giving a stable and direct convergence path.
Cons: Computationally expensive and memory-intensive on large datasets; infeasible to load millions of samples into memory at once.
Stochastic Gradient Descent (SGD)
In Stochastic Gradient Descent, we calculate the gradient and update the parameters using just one training sample at a time. The gradient approximation reads as follows:
\[ \nabla_{\boldsymbol \theta} L(\boldsymbol{\theta}^{(t-1)}) \approx \nabla_{\boldsymbol \theta} \ell_i(\boldsymbol{\theta}^{(t-1)}) \quad \text{for a single random sample } i \]
Using only one data point per update instead of all \(i = 1, \dots, N\) is a coarse approximation to the full gradient.
Note
Pros: Fast per update and requires little memory; the noisy updates can also help the model escape shallow local minima.
Cons: The path to the minimum is noisy and erratic; with a constant step size the iterates do not converge to a fixed point but bounce around the minimum. Convergence is recovered with a diminishing step-size schedule satisfying the Robbins–Monro conditions \(\sum_t \eta_t = \infty\) and \(\sum_t \eta_t^2 < \infty\)(Robbins and Monro 1951).
Mini-Batch Gradient Descent
Mini-Batch Gradient Descent is the standard approach in deep learning, balancing batch and SGD. The gradient is computed on a small, random subset of the data called a mini-batch.
More precisely: We first define \(J\) batches \(B_j\) such that \(\bigcup_{j=1}^J B_j = \{1,\ldots,N\}\) and \(B_j \cap B_{j'} = \emptyset \quad \text{ for all } j,j' = 1,\ldots,J:\ j \neq j'\). With learning rate \(\eta > 0\) and starting value \(\boldsymbol{\theta}^{(0)}\), we get the following gradient approximation for the selected batch \(B_j\):
A typical mini-batch size \(b = |B_j|\) is 32, 64, or 128. The total number of iteration steps for the algorithm \(T\) doesn’t need to coincide with the number of batches \(J\). Typically, we have \(J \ll T\) such that, after going through all batches for updating the parameters, we draw new batches of the same size to continue updating our parameter.
Note
Pros: Mini-Batch Gradient Descent balances the stability of Batch Gradient Descent with the speed of SGD. It also allows for efficient computation using vectorized operations on modern hardware (GPUs).
Cons: It introduces an additional hyperparameter (the batch size) to (potentially) tune.
If you take - \(|B_j| = 1\) for each batch used in the update, then we are back at SGD, and - \(J = 1\) with \(B_1 = \{1,\ldots,N\}\) reduces to Batch Gradient Descent.
Question for Reflection
If observations are ordered over time or clustered by firm, what econometric concern is raised by randomly sampled mini-batches, and what kind of batch construction would better preserve the dependence structure?
Suggested Answer
Random mini-batches can break the local dependence structure and mix observations from different firms or time periods. This may still be useful computationally, but the resulting gradient noise no longer reflects the dependence pattern in the data. For time-series or panel problems, batches that keep time blocks or firm clusters together can be more appropriate when dependence or real-time information sets matter.
Definition: Epoch
An epoch refers to one full pass through the training data. With this notion introduced, we get the following pseudocode for mini-batch optimization in supervised learning:
Define \(n_e, n_{e,b} \in \mathbb{N}\setminus\{0\}\) the number of epochs for training and the number of batches for each epoch, respectively.
Algorithm: Mini-Batch Gradient Descent Training
Input: Training data \(\{(x_i, y_i)\}_{i=1}^N\), learning rate \(\eta\), batch size \(|B_j|\)
Initialize:\(\boldsymbol{\theta}^{(0)}\), set \(t = 0\)
Repeat for\(e = 1, \ldots, n_e\)(epochs):
Shuffle training data \(\{(x_i, y_i)\}_{i=1}^N\)
For each batch\(B_j\) where \(j = 1, \ldots, n_{e,b}\):
Compute fitted values:\(\hat{y}_i = f(x_i; \boldsymbol{\theta}^{(t)})\) for all observations in \(B_j\)
Stopping rule: Stop if a convergence criterion is reached or the maximum number of iterations \(T\) is reached
Output: Final parameters \(\boldsymbol{\theta}^{(t^\ast)}\), where \(t^\ast\) is the realized stopping iteration
4.6 Challenges and Advanced Optimizers
Challenges with Vanilla Gradient Descent
Choosing the right learning rate \(\eta\) is difficult
The same learning rate applies to all parameters, which may not be ideal
It can get stuck in saddle points, where the gradient is zero but the point is neither a local minimum nor a local maximum, which are common in high-dimensional landscapes (Dauphin et al. 2014)
To address these issues, researchers have developed adaptive optimization algorithms that adjust the learning rate for each parameter automatically.
In all of the following algorithms, we choose a learning rate \(\eta > 0\) and a starting value \(\boldsymbol{\theta}^{(0)}\). Consider iteration steps \(t = 1,\ldots,T\), and define \(\boldsymbol g_t = \frac{1}{N} \sum_{i = 1}^N \nabla_{\boldsymbol{\theta}}\ell_i(\boldsymbol{\theta}^{(t-1)})\) as the gradient used for the \(t\)th update. We can combine all methods below with mini-batches, but leave this out for brevity in notation.
Momentum
The momentum idea traces to Polyak (1964), who introduced the “heavy ball” method to accelerate iterative optimization, and Nesterov (1983), whose accelerated-gradient variant achieves a provably better convergence rate on convex objectives. A function is convex if its graph lies below every chord joining two points on it, equivalently if its Hessian is positive semidefinite; convex objectives have no spurious local minima (every local minimum is global), which is why convergence guarantees are typically stated for them. Momentum accelerates SGD in directions of persistent gradient and dampens oscillations. It does so by adding a fraction of the previous update vector to the current gradient, creating a “velocity” term that accumulates past gradients.
Here, \(\delta \in [0,1)\) is the momentum coefficient, and the velocity \(v_t\) accumulates a weighted average of past gradients. This creates a “ball rolling downhill” effect that helps overcome small local minima and accelerates convergence in consistent directions.
AdaGrad (Adaptive Gradient)
AdaGrad adapts the learning rate for each parameter individually, performing larger updates for infrequent parameters and smaller updates for frequent ones (Duchi, Hazan, and Singer 2011). It achieves this by dividing the learning rate by the square root of the sum of all past squared gradients for that parameter.
Two versions appear in the literature. The full-matrix version accumulates the outer products
This form is mathematically clean but computationally infeasible in modern networks: storing and inverting an \(m \times m\) matrix with \(m\) in the millions is impractical. The version actually used in software (and called AdaGrad below) replaces the full matrix with its diagonal: define the elementwise gradient accumulator
The small constant \(\varepsilon > 0\) is a smoothing term that prevents division by zero. Throughout this book, AdaGrad refers to the diagonal version unless stated otherwise.
Note
Pros: Excellent for sparse data (like in NLP), where some features appear infrequently.
Cons: The denominator \(\sqrt{\boldsymbol G_t + \varepsilon}\) grows monotonically. This causes the effective learning rate to eventually become infinitesimally small, effectively stopping the training process.
RMSprop (Root Mean Square Propagation)
RMSprop modifies AdaGrad to resolve its main issue of a learning rate that aggressively and monotonically decreases. Instead of accumulating all past squared gradients, RMSprop uses an exponentially decaying average, preventing the denominator from growing endlessly. Define \(g_t\) as above and \(g_t^2\) as the elementwise product of \(g_t\) times \(g_t\); that is, \(g_t^2 = g_t \odot g_t\).
The update rules are (with \(v_0 = 0\)):
Compute decaying average of squared gradients: \[ \boldsymbol v_t = \gamma \boldsymbol v_{t-1} + (1 - \gamma) \boldsymbol g_t^2 \]
Update parameters: \[ \boldsymbol{\theta}^{(t)} = \boldsymbol{\theta}^{(t-1)} - \eta \frac{1}{\sqrt{v_t} + \varepsilon}g_t \] Here, \(v_t\) is the moving average of squared gradients, and \(\gamma\) is the squared-gradient decay rate (e.g., 0.9), distinct from the momentum coefficient \(\delta\) above. By “forgetting” the distant past, RMSprop keeps the learning rate adaptive and responsive throughout training.
Adam (Adaptive Moment Estimation)
Adam is a widely used default optimizer for neural networks (Kingma and Ba 2015). It combines the ideas of Momentum (using the first moment, or mean, of the gradients) and RMSprop (using the second moment, or uncentered variance, of the gradients).
The algorithm maintains two moving averages:
First moment estimate (momentum), with first-moment decay \(\beta_1\): \[ \boldsymbol m_t = \beta_1 \boldsymbol m_{t-1} + (1 - \beta_1) \boldsymbol g_{t} \]
Second moment estimate (uncentered variance), with second-moment decay \(\beta_2\): \[ \boldsymbol v_t = \beta_2 \boldsymbol v_{t-1} + (1 - \beta_2) \boldsymbol g_{t}^2 \]
Here \(\beta_1,\beta_2 \in [0,1)\) play the roles that \(\delta\) and \(\gamma\) played for Momentum and RMSprop, respectively. Since \(\boldsymbol m_t\) and \(\boldsymbol v_t\) are initialized as zero vectors, they are biased toward zero, especially during the initial time steps. Unrolling the recursion gives \(\boldsymbol m_t = (1-\beta_1) \sum_{\tau=1}^{t} \beta_1^{t-\tau} \boldsymbol g_\tau\), so under a stationary gradient process with \(\mathbb{E}[\boldsymbol g_\tau] = \boldsymbol \mu\) we have \(\mathbb{E}[\boldsymbol m_t] = (1-\beta_1^t)\boldsymbol \mu\). Adam corrects this bias by rescaling:
The correction restores unbiasedness under stationarity; during actual training, gradient means and second moments drift across iterations, so the correction is approximate but still removes most of the initial zero-init bias.
Adam is generally a good default choice for most deep learning problems due to its robustness and adaptive nature. A modern variant is AdamW(Loshchilov and Hutter 2019), which decouples weight decay from the adaptive gradient update; this makes the regularization effect easier to tune than in vanilla Adam with an ordinary \(L_2\) penalty.
4.7 Optimizer Comparison
The column Optimizer state reports the number of running state tensors the optimizer stores per parameter (on top of the parameter vector itself). It reflects the memory overhead of the update rule and should not be confused with dataset memory, which is controlled separately by the batch size.
Algorithm
Optimizer state
Hyperparameters
Key Advantage
Key Limitation
Batch Gradient Descent
0
\(\eta\)
Stable, smooth convergence
Very slow; loads the full dataset per step
SGD
0
\(\eta\)
Fast per iteration
Noisy, sensitive to \(\eta\)
Mini-Batch Gradient Descent
0
\(\eta\), batch size
Balances speed and stability
Additional hyperparameter to tune
Momentum
1 (velocity)
\(\eta\), \(\delta\)
Accelerates convergence, dampens oscillations
Can overshoot, needs tuning
AdaGrad
1 (squared-gradient sum)
\(\eta\), \(\epsilon\)
Adapts per-parameter rates
Learning rate decays to zero
RMSprop
1 (EMA of squared gradients)
\(\eta\), \(\gamma\), \(\epsilon\)
Fixes AdaGrad’s decay problem
No momentum component
Adam
2 (first and second moments)
\(\eta\), \(\beta_1\), \(\beta_2\), \(\epsilon\)
Combines momentum + adaptation
Can converge to suboptimal points
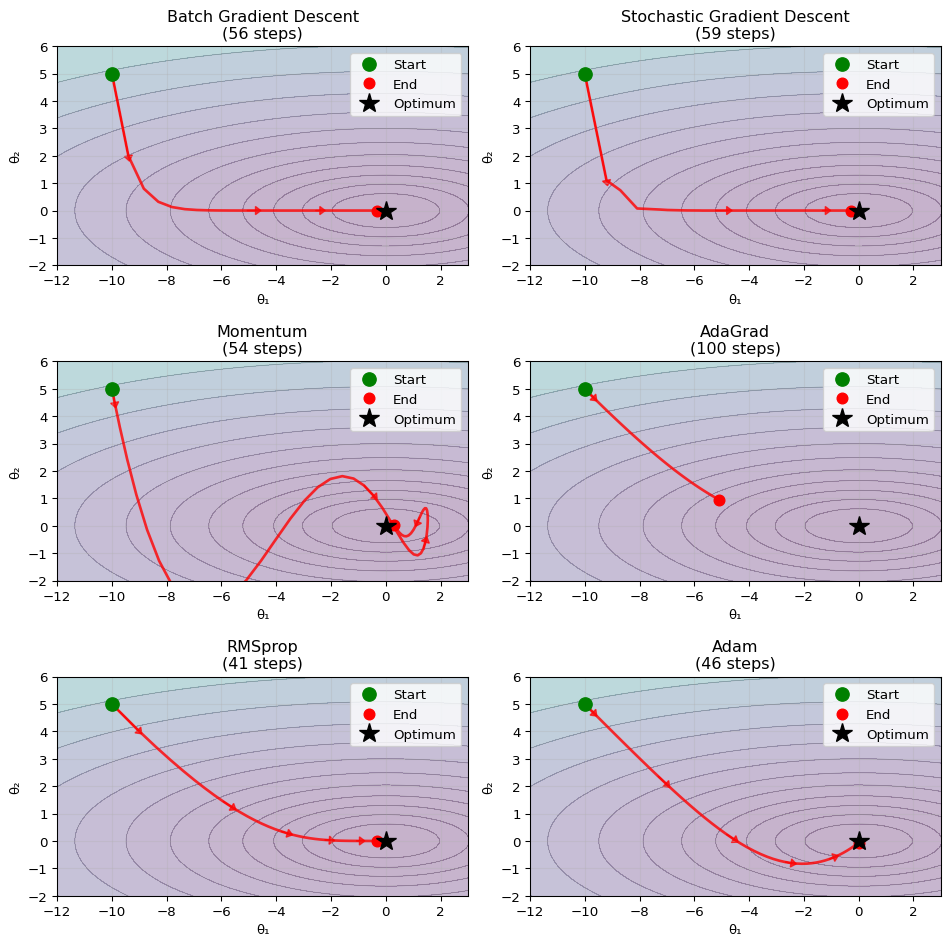
4.8 Visualizing Optimizers
The following plot shows the paths taken by different optimizers on a contour plot of the loss function
\[
l(x,y)=1+0.1x^2+y^2.
\]
The algorithms stop after at most 100 iterations, with stopping criterion \(l(x,y)<1.01\) (close to the global minimum value of 1). Most optimizers use a learning rate of 0.3; the momentum panel uses 0.5 because the convex-combination velocity \(v_t = \delta v_{t-1} + (1-\delta)g_t\) already shrinks the effective step by roughly \(1-\delta\). The SGD path is illustrated by adding mini-batch-style noise to the gradient update, since there is no actual dataset behind the contour. Code is foldable via “Show the code”.
Show the code
import numpy as npimport matplotlib.pyplot as plt# Set random seed for reproducibilitynp.random.seed(42)# Define loss function (less elongated for clearer visualization)def f(x, y):return1+0.1* x**2+1* y**2# Less extreme ratiodef df(x, y):return0.2* x, 2* y# Create contour plotx = np.linspace(-12, 12, 100)y = np.linspace(-8, 8, 100)X, Y = np.meshgrid(x, y)Z = f(X, Y)def run_batch_gd(x0, y0, lr=0.3, n_steps=100):"""Pure batch gradient descent - smooth path""" path = [(x0, y0)] x, y = x0, y0for _ inrange(n_steps): gx, gy = df(x, y) x -= lr * gx y -= lr * gy path.append((x, y))if f(x, y) <1.01:breakreturn np.array(path)def run_sgd(x0, y0, lr=0.3, n_steps=100):"""Realistic SGD - simulate mini-batch variance""" path = [(x0, y0)] x, y = x0, y0# Generate synthetic dataset that creates natural variance np.random.seed(123) # Different seed for data generation data_variance =0.3# Controls how much mini-batches differfor step inrange(n_steps):# Each mini-batch has slightly different gradient estimate gx_base, gy_base = df(x, y)# Add realistic mini-batch variance (not just random noise) gx_noise = np.random.normal(0, data_variance *abs(gx_base *1)) gy_noise = np.random.normal(0, data_variance *abs(gy_base *1)) gx = gx_base + gx_noise gy = gy_base + gy_noise x -= lr * gx y -= lr * gy path.append((x, y))if f(x, y) <1.01:breakreturn np.array(path)def run_momentum(x0, y0, lr=0.5, beta=0.9, n_steps=100):"""Momentum optimizer with convex-combination velocity (matches the text).""" path = [(x0, y0)] x, y = x0, y0 vx, vy =0, 0# Initialize velocityfor _ inrange(n_steps): gx, gy = df(x, y)# Velocity as convex combination (matches v_t = beta v_{t-1} + (1 - beta) g_t) vx = beta * vx + (1- beta) * gx vy = beta * vy + (1- beta) * gy# Update parameters x -= lr * vx y -= lr * vy path.append((x, y))if f(x, y) <1.01:breakreturn np.array(path)def run_adagrad(x0, y0, lr=0.3, eps=1e-8, n_steps=100):"""AdaGrad optimizer - shows stalling behavior""" path = [(x0, y0)] x, y = x0, y0 gx_sum_sq, gy_sum_sq =0, 0for step inrange(n_steps): gx, gy = df(x, y)# Accumulate squared gradients gx_sum_sq += gx**2 gy_sum_sq += gy**2# AdaGrad update - learning rate decreases over time effective_lr_x = lr / (np.sqrt(gx_sum_sq) + eps) effective_lr_y = lr / (np.sqrt(gy_sum_sq) + eps) x -= effective_lr_x * gx y -= effective_lr_y * gy path.append((x, y))# More lenient stopping criterion to see stallingif f(x, y) <1.01and step >20:break# Stop if steps become too small (stalling)if step >10and effective_lr_x <1e-4and effective_lr_y <1e-4:breakreturn np.array(path)def run_rmsprop(x0, y0, lr=0.3, gamma=0.9, eps=1e-8, n_steps=100):"""RMSprop optimizer - maintains learning rate""" path = [(x0, y0)] x, y = x0, y0 vx, vy =0, 0for step inrange(n_steps): gx, gy = df(x, y)# Update moving average of squared gradients vx = gamma * vx + (1- gamma) * gx**2 vy = gamma * vy + (1- gamma) * gy**2# RMSprop update - learning rate stays more stable effective_lr_x = lr / (np.sqrt(vx) + eps) effective_lr_y = lr / (np.sqrt(vy) + eps) x -= effective_lr_x * gx y -= effective_lr_y * gy path.append((x, y))# Same stopping criterionif f(x, y) <1.01and step >20:breakreturn np.array(path)def run_adam(x0, y0, lr=0.3, beta1=0.9, beta2=0.999, eps=1e-8, n_steps=100):"""Adam optimizer""" path = [(x0, y0)] x, y = x0, y0 mx, my =0, 0 vx, vy =0, 0for t inrange(1, n_steps +1): gx, gy = df(x, y)# Update moments mx = beta1 * mx + (1- beta1) * gx my = beta1 * my + (1- beta1) * gy vx = beta2 * vx + (1- beta2) * gx**2 vy = beta2 * vy + (1- beta2) * gy**2# Bias correction mx_hat = mx / (1- beta1**t) my_hat = my / (1- beta1**t) vx_hat = vx / (1- beta2**t) vy_hat = vy / (1- beta2**t)# Update parameters x -= lr * mx_hat / (np.sqrt(vx_hat) + eps) y -= lr * my_hat / (np.sqrt(vy_hat) + eps) path.append((x, y))if f(x, y) <1.01:breakreturn np.array(path)# Run all optimizers from the same starting pointstart_x, start_y =-10, 5path_batch = run_batch_gd(start_x, start_y)path_sgd = run_sgd(start_x, start_y)path_momentum = run_momentum(start_x, start_y)path_adagrad = run_adagrad(start_x, start_y)path_rmsprop = run_rmsprop(start_x, start_y)path_adam = run_adam(start_x, start_y)# Plot - using 2x3 grid to accommodate all 6 optimizersfig, axes = plt.subplots(3, 2, figsize=(10, 10))axes = axes.flatten()paths_and_titles = [ (path_batch, 'Batch Gradient Descent'), (path_sgd, 'Stochastic Gradient Descent'), (path_momentum, 'Momentum'), (path_adagrad, 'AdaGrad'), (path_rmsprop, 'RMSprop'), (path_adam, 'Adam')]for i, (path, title) inenumerate(paths_and_titles): ax = axes[i]# Create contour background levels = np.logspace(0, 2, 15) # Better level spacing ax.contour(X, Y, Z, levels=levels, alpha=0.6, colors='gray', linewidths=0.5) ax.contourf(X, Y, Z, levels=levels, alpha=0.3, cmap='viridis')# Plot optimization path ax.plot(path[:, 0], path[:, 1], 'r-', linewidth=2, alpha=0.8) ax.plot(path[0, 0], path[0, 1], 'go', markersize=10, label='Start', zorder=5) ax.plot(path[-1, 0], path[-1, 1], 'ro', markersize=8, label='End', zorder=5) ax.plot(0, 0, 'k*', markersize=15, label='Optimum', zorder=5)# Add arrows to show direction (fewer arrows for clarity)iflen(path) >5: arrow_indices = np.linspace(0, len(path)-2, min(6, len(path)-1), dtype=int)for j in arrow_indices: dx = path[j+1, 0] - path[j, 0] dy = path[j+1, 1] - path[j, 1]# Only draw arrow if movement is significantif np.sqrt(dx**2+ dy**2) >0.1: ax.arrow(path[j, 0], path[j, 1], dx, dy, head_width=0.3, head_length=0.2, fc='red', ec='red', alpha=0.7) ax.set_aspect('equal', adjustable='box') ax.set_title(f'{title}\n({len(path)-1} steps)') ax.set_xlabel('θ₁') ax.set_ylabel('θ₂') ax.legend(loc='upper right') ax.grid(True, alpha=0.3) ax.set_xlim(-12, 3) ax.set_ylim(-2, 6)plt.tight_layout()plt.show()
Figure 4.1: Comparison of different optimization algorithms on a 2D loss landscape.
Note on Algorithm Performance
While Adam might not appear dramatically superior to other algorithms in this visualization, keep in mind that we’re using a very well-behaved quadratic function for demonstration purposes. In practice, neural network loss landscapes are:
Highly non-convex with many local minima and saddle points
High-dimensional (often millions of parameters)
Ill-conditioned with vastly different scales across parameters; ill-conditioning is measured by the condition number \(\kappa = \lambda_{\max}/\lambda_{\min}\), the ratio of the largest to the smallest eigenvalue of the Hessian (the largest to smallest curvature), with large \(\kappa\) indicating a poorly conditioned, hard-to-optimize landscape
Noisy due to mini-batch sampling
In such challenging real-world scenarios, Adam’s adaptive learning rates and momentum typically provide significant advantages over simpler methods. This simple 2D example serves to illustrate the core behavioral differences between optimizers rather than their relative performance on complex problems.
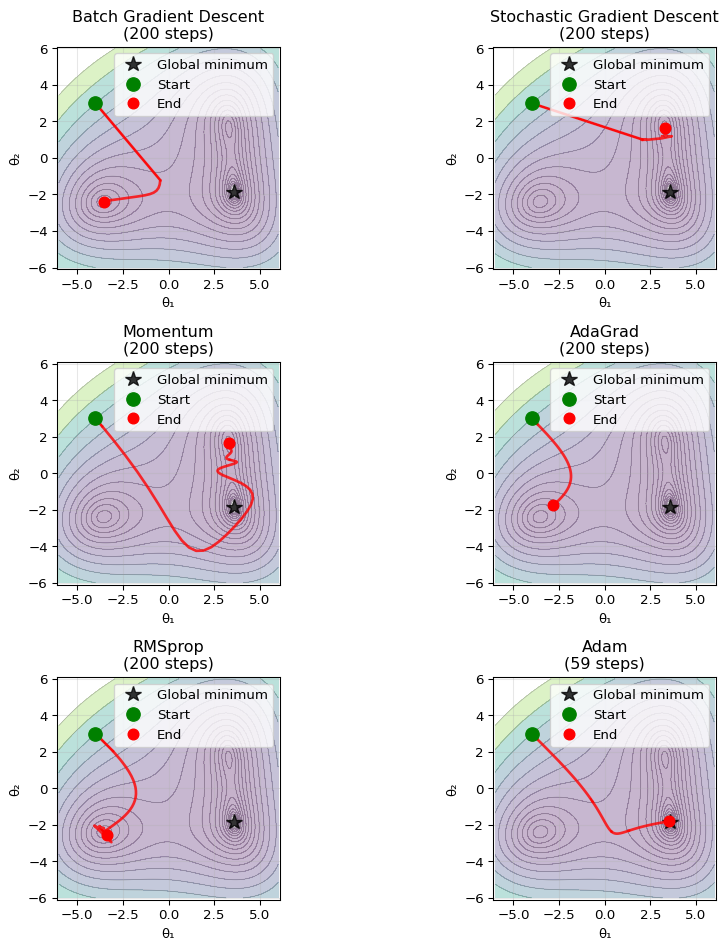
We can make the minimization problem more challenging by having multiple local minima and one global minimum. Of course, depending on the hyperparameters chosen, all algorithms may find the global minimum. The goal is to find an optimizer that is largely robust to different choices of hyperparameters.
Show the code
import numpy as npimport matplotlib.pyplot as plt# Set random seed for reproducibilitynp.random.seed(42)# Define a more challenging non-convex function with multiple local minimadef f_nonconvex(x, y):return2/3* ((x**2+ y -11)**2+ (x + y**2-7)**2+ (x -4)**2* (y +2)**2)def df_nonconvex(x, y):# Partial derivative with respect to x dx = (2/3) * (4*x*(x**2+ y -11) +2*(x + y**2-7) +2*(x -4)*(y +2)**2)# Partial derivative with respect to y dy = (2/3) * (2*(x**2+ y -11) +4*y*(x + y**2-7) +2*(x -4)**2*(y +2))return dx, dy# Create contour plot for non-convex functionx_nc = np.linspace(-6, 6, 600)y_nc = np.linspace(-6, 6, 600)X_nc, Y_nc = np.meshgrid(x_nc, y_nc)Z_nc = f_nonconvex(X_nc, Y_nc)def run_optimizer_nonconvex(optimizer_func, x0, y0, **kwargs):"""Generic wrapper for running optimizers on non-convex function""" path = [(x0, y0)] x, y = x0, y0if'momentum'in optimizer_func.__name__: vx, vy =0, 0 lr = kwargs.get('lr', 0.3) beta = kwargs.get('beta', 0.9) n_steps = kwargs.get('n_steps', 200)for _ inrange(n_steps): gx, gy = df_nonconvex(x, y) vx = beta * vx + (1- beta) * gx vy = beta * vy + (1- beta) * gy x -= lr * vx y -= lr * vy path.append((x, y))if f_nonconvex(x, y) <1or np.isnan(x) or np.isnan(y):breakelif'adagrad'in optimizer_func.__name__: gx_sum_sq, gy_sum_sq =0, 0 lr = kwargs.get('lr', 0.3) eps = kwargs.get('eps', 1e-8) n_steps = kwargs.get('n_steps', 200)for step inrange(n_steps): gx, gy = df_nonconvex(x, y) gx_sum_sq += gx**2 gy_sum_sq += gy**2 effective_lr_x = lr / (np.sqrt(gx_sum_sq) + eps) effective_lr_y = lr / (np.sqrt(gy_sum_sq) + eps) x -= effective_lr_x * gx y -= effective_lr_y * gy path.append((x, y))if f_nonconvex(x, y) <1or np.isnan(x) or np.isnan(y):breakif step >10and effective_lr_x <1e-6and effective_lr_y <1e-6:breakelif'rmsprop'in optimizer_func.__name__: vx, vy =0, 0 lr = kwargs.get('lr', 0.3) gamma = kwargs.get('gamma', 0.9) eps = kwargs.get('eps', 1e-8) n_steps = kwargs.get('n_steps', 200)for _ inrange(n_steps): gx, gy = df_nonconvex(x, y) vx = gamma * vx + (1- gamma) * gx**2 vy = gamma * vy + (1- gamma) * gy**2 x -= lr * gx / (np.sqrt(vx) + eps) y -= lr * gy / (np.sqrt(vy) + eps) path.append((x, y))if f_nonconvex(x, y) <1or np.isnan(x) or np.isnan(y):breakelif'adam'in optimizer_func.__name__: mx, my =0, 0 vx, vy =0, 0 lr = kwargs.get('lr', 0.3) beta1 = kwargs.get('beta1', 0.9) beta2 = kwargs.get('beta2', 0.99) eps = kwargs.get('eps', 1e-8) n_steps = kwargs.get('n_steps', 200)for t inrange(1, n_steps +1): gx, gy = df_nonconvex(x, y) mx = beta1 * mx + (1- beta1) * gx my = beta1 * my + (1- beta1) * gy vx = beta2 * vx + (1- beta2) * gx**2 vy = beta2 * vy + (1- beta2) * gy**2 mx_hat = mx / (1- beta1**t) my_hat = my / (1- beta1**t) vx_hat = vx / (1- beta2**t) vy_hat = vy / (1- beta2**t) x -= lr * mx_hat / (np.sqrt(vx_hat) + eps) y -= lr * my_hat / (np.sqrt(vy_hat) + eps) path.append((x, y))if f_nonconvex(x, y) <1or np.isnan(x) or np.isnan(y):breakelif'sgd'in optimizer_func.__name__: lr = kwargs.get('lr', 0.3) n_steps = kwargs.get('n_steps', 200) np.random.seed(456) # Different seed for SGD noise data_variance =0.2for _ inrange(n_steps): gx_base, gy_base = df_nonconvex(x, y) gx_noise = np.random.normal(0, data_variance *abs(gx_base *5.3)) gy_noise = np.random.normal(0, data_variance *abs(gy_base *5.3)) gx = gx_base + gx_noise gy = gy_base + gy_noise x -= lr * gx y -= lr * gy path.append((x, y))if f_nonconvex(x, y) <1or np.isnan(x) or np.isnan(y):breakelse: # Batch GD lr = kwargs.get('lr', 0.3) n_steps = kwargs.get('n_steps', 200)for _ inrange(n_steps): gx, gy = df_nonconvex(x, y) x -= lr * gx y -= lr * gy path.append((x, y))if f_nonconvex(x, y) <1or np.isnan(x) or np.isnan(y):breakreturn np.array(path)# Define dummy functions for the wrapperdef run_batch_gd_nc(): passdef run_sgd_nc(): passdef run_momentum_nc(): passdef run_adagrad_nc(): passdef run_rmsprop_nc(): passdef run_adam_nc(): pass# Run all optimizers from the same challenging starting pointstart_x_nc, start_y_nc =-4, 3# Start far from any minimumpath_batch_nc = run_optimizer_nonconvex(run_batch_gd_nc, start_x_nc, start_y_nc, lr=0.01)path_sgd_nc = run_optimizer_nonconvex(run_sgd_nc, start_x_nc, start_y_nc, lr=0.01)path_momentum_nc = run_optimizer_nonconvex(run_momentum_nc, start_x_nc, start_y_nc, lr=0.001, beta=0.9)path_adagrad_nc = run_optimizer_nonconvex(run_adagrad_nc, start_x_nc, start_y_nc, lr=0.3)path_rmsprop_nc = run_optimizer_nonconvex(run_rmsprop_nc, start_x_nc, start_y_nc, lr=0.3)path_adam_nc = run_optimizer_nonconvex(run_adam_nc, start_x_nc, start_y_nc, lr=0.3)# Plot - using 2x3 grid for all 6 optimizersfig, axes = plt.subplots(3, 2, figsize=(10, 10))axes = axes.flatten()paths_and_titles_nc = [ (path_batch_nc, 'Batch Gradient Descent'), (path_sgd_nc, 'Stochastic Gradient Descent'), (path_momentum_nc, 'Momentum'), (path_adagrad_nc, 'AdaGrad'), (path_rmsprop_nc, 'RMSprop'), (path_adam_nc, 'Adam')]# Known global minima of Himmelblau's functionglobal_minima = [(3.584428, -1.848126)]for i, (path, title) inenumerate(paths_and_titles_nc): ax = axes[i]# Create contour background - use log scale for better visualization levels = np.logspace(0, 3.4, 20) ax.contour(X_nc, Y_nc, Z_nc, levels=levels, alpha=0.6, colors='gray', linewidths=0.5) ax.contourf(X_nc, Y_nc, Z_nc, levels=levels, alpha=0.3, cmap='viridis')# Plot the known global minimum once per panel gm_x, gm_y = global_minima[0] ax.plot(gm_x, gm_y, 'k*', markersize=12, alpha=0.8, label='Global minimum')# Plot optimization pathiflen(path) >1: ax.plot(path[:, 0], path[:, 1], 'r-', linewidth=2, alpha=0.8) ax.plot(path[0, 0], path[0, 1], 'go', markersize=10, label='Start', zorder=5) ax.plot(path[-1, 0], path[-1, 1], 'ro', markersize=8, label='End', zorder=5)# Add arrows for direction (fewer for clarity)iflen(path) >5: arrow_indices = np.linspace(0, len(path)-2, min(5, len(path)-1), dtype=int)for j in arrow_indices: dx = path[j+1, 0] - path[j, 0] dy = path[j+1, 1] - path[j, 1]if np.sqrt(dx**2+ dy**2) >0.05: ax.arrow(path[j, 0], path[j, 1], dx, dy, head_width=0.1, head_length=0.08, fc='red', ec='red', alpha=0.7) ax.set_aspect('equal', adjustable='box') ax.set_title(f'{title}\n({len(path)-1} steps)') ax.set_xlabel('θ₁') ax.set_ylabel('θ₂') ax.legend(loc='upper right') ax.grid(True, alpha=0.3) ax.set_xlim(-6.1, 6.1) ax.set_ylim(-6.1, 6.1)plt.tight_layout()plt.show()
Figure 4.2: Comparison of optimization algorithms on a non-convex loss landscape with multiple local minima.
4.9 Summary
Key Takeaways
Gradient descent is the basic optimization idea underlying modern neural-network training: update parameters in the direction of steepest descent.
Mini-batch gradient descent is the practical standard because it balances computational efficiency with relatively stable gradient information.
Learning-rate choice is central: too small leads to painfully slow progress, while too large leads to instability.
Advanced optimizers such as Momentum, AdaGrad, RMSprop, and Adam modify vanilla gradient descent to improve stability, speed, or parameter-specific adaptation.
Adam is often a strong default in practice, but optimizer choice matters more when the loss surface is non-convex, noisy, and high-dimensional.
Common Pitfalls
Learning Rate Issues
Too high: Training becomes unstable, loss explodes
Too low: Training is painfully slow, may get stuck in poor local minima
Solution: Use adaptive optimizers like Adam, or learning rate schedules
Overfitting to Simple Examples
Don’t judge optimizers solely on toy 2D functions
Real neural networks have millions of parameters and complex loss landscapes
What works on simple problems may not scale to “deep learning”
4.10 Exercises
Exercise 4.1: Learning Rates in an Ill-Conditioned Quadratic Problem
Derive the gradient and show that the updates satisfy \[
\theta_1^{(t+1)}=(1-\eta a)\theta_1^{(t)},
\qquad
\theta_2^{(t+1)}=(1-\eta b)\theta_2^{(t)}.
\]
Show that convergence to \((0,0)\) requires \[
0<\eta<\frac{2}{a}.
\]
Explain why, when \(a\gg b\), a single global learning rate creates a tension between fast progress in the \(\theta_2\) direction and stability in the \(\theta_1\) direction. Relate this to the motivation for adaptive or preconditioned optimization methods.
Exam level. The exercise formalizes why optimization becomes difficult in ill-conditioned problems and why a single learning rate can be inadequate.
Hint for Part 1
Differentiate the quadratic objective coordinate by coordinate.
Hint for Part 2
A scalar recursion \(x_{t+1}=cx_t\) converges to zero if and only if \(|c|<1\).
Hint for Part 3
Compare the learning rate that would be natural for the flat direction, \(1/b\), with the stability restriction coming from the steep direction.
Since \(a>b\), we have \(\frac{2}{a}<\frac{2}{b}\), so the binding restriction is
\[
0<\eta<\frac{2}{a}.
\]
Part 3: Why Ill-Conditioning Slows Optimization
If \(a\gg b\), then the objective is much steeper in the \(\theta_1\) direction than in the \(\theta_2\) direction. Stability forces
\[
\eta<\frac{2}{a},
\]
which can be very small. But then the update factor in the flat direction is
\[
1-\eta b,
\]
which stays close to 1, so convergence along \(\theta_2\) is very slow.
Thus a single global learning rate cannot be simultaneously well-tuned for both directions: a larger \(\eta\) would help progress in the flat direction but would destabilize the steep direction. This is one of the main motivations for adaptive or preconditioned methods, which scale updates differently across coordinates.
Exercise 4.2: Mini-Batch Gradients as Noisy Gradient Estimators
Show that \[
\mathbb{E}\left[\hat g_B(\boldsymbol{\theta})\right] = g(\boldsymbol{\theta}),
\] so the mini-batch gradient is an unbiased estimator of the full gradient.
Consider the scalar case where \(\nabla_{\boldsymbol{\theta}} \ell_i(\boldsymbol{\theta})\) is replaced by \(z_i \in \mathbb{R}\). Show that \[
\mathrm{Var}\left(\frac{1}{b}\sum_{i\in B} z_i\right)
=
\frac{N-b}{b(N-1)} \cdot \frac{1}{N}\sum_{i=1}^N (z_i-\bar z)^2,
\] where \(\bar z = \frac{1}{N}\sum_{i=1}^N z_i\).
Use Part 2 to explain why smaller mini-batches (smaller \(b\)) produce noisier updates. Then explain one reason why such noise may nevertheless be useful in optimization.
Exam level. The exercise formalizes why mini-batch updates are noisy but still useful approximations to the full gradient.
Hint for Part 1
Write the mini-batch estimator as an average of terms multiplied by inclusion indicators.
Hint for Part 2
Use the standard variance formula for sampling without replacement, or derive it from inclusion probabilities.
Hint for Part 3
Inspect the factor
\[
\frac{N-b}{b(N-1)}.
\]
Solution
Part 1: Unbiasedness of the Mini-Batch Gradient
Let
\[
\mathbb{1}\{i \in B\}
\]
denote the inclusion indicator for observation \(i\). Then
falls as \(b\) increases. Therefore smaller mini-batches produce noisier gradient estimates and hence noisier parameter updates.
That noise can nevertheless be useful because it can prevent the algorithm from following a rigid deterministic path. In non-convex problems, moderate noise may help the optimizer move away from poor local geometries such as narrow basins or saddle regions.
Note
Before moving on to neural networks, note the chapter boundary: so far the objects being optimized were generic objective functions. In the next chapter, the same optimization ideas are applied to feed-forward networks, where gradients are computed by backpropagation.
where \(\eta>0\) is the learning rate and \(\delta\in[0,1)\) is the momentum parameter.
Eliminate \(v_t\) and show that \(\theta_t\) satisfies the second-order recursion \[
\theta_{t+1}
=
\big(1+\delta-\eta(1-\delta)a\big)\theta_t
-\delta \theta_{t-1}.
\]
Show that when \(\delta=0\) this reduces to the gradient descent recursion from Exercise 4.1. For the general case, use the following Schur-Cohn stability criterion (see, e.g., Hamilton 1994): a second-order linear recursion \(x_{t+1}=cx_t+dx_{t-1}\) with characteristic polynomial \(p(\lambda)=\lambda^2-c\lambda-d\) converges to zero if and only if \(p(1)>0\), \(p(-1)>0\), and \(|d|<1\). Apply this to show that, for general \(\delta\in[0,1)\), the recursion converges to zero if and only if \[
\eta<\frac{2(1+\delta)}{(1-\delta)\,a}.
\]
Compare this stability bound with the vanilla gradient descent bound \(\eta<2/a\). Explain why momentum widens the range of stable learning rates and why, despite this, momentum can still produce oscillatory transient behavior.
Exam level. The exercise turns momentum into a concrete dynamic system, derives its stability region, and compares it with vanilla gradient descent.
Hint for Part 1
Use the update equation at times \(t\) and \(t-1\) to write
\[
v_{t-1}=\frac{\theta_{t-1}-\theta_t}{\eta}.
\]
Hint for Part 2
When \(\delta=0\) the lagged term vanishes. For the general case, identify \(c\) and \(d\) in the given stability criterion by matching the recursion to the form \(x_{t+1}=cx_t+dx_{t-1}\). Then evaluate \(p(1)\), \(p(-1)\), and \(|d|\) separately.
Hint for Part 3
Compare the bound at \(\delta=0\) and \(\delta>0\). For oscillation, consider when the discriminant of the characteristic polynomial is negative, so the roots are complex.
Using \(\theta_{t+1}=\theta_t-\eta v_t\), we obtain \[\begin{align*}
\theta_{t+1}
&=
\theta_t-\eta\left[\delta \frac{\theta_{t-1}-\theta_t}{\eta}+(1-\delta)a\theta_t\right] \\
&=
\theta_t-\delta(\theta_{t-1}-\theta_t)-\eta(1-\delta)a\theta_t \\
&=
\big(1+\delta-\eta(1-\delta)a\big)\theta_t-\delta\theta_{t-1}.
\end{align*}\]
Part 2: Stability Analysis
When \(\delta=0\), the recursion becomes \(\theta_{t+1}=(1-\eta a)\theta_t\), which is the gradient descent recursion from Exercise 4.1. This converges iff \(|1-\eta a|<1\), i.e., \(0<\eta<2/a\).
For general \(\delta\in[0,1)\), write \(c=1+\delta-\eta(1-\delta)a\). The recursion has characteristic polynomial
\[
p(\lambda)=\lambda^2-c\lambda+\delta.
\]
By the stability criterion given in the exercise, convergence requires \(p(1)>0\), \(p(-1)>0\), and \(|\delta|<1\).
\(p(1)=1-c+\delta=\eta(1-\delta)a>0\), which always holds.
At \(\delta=0\) the bound is \(\eta<2/a\). For \(\delta>0\) the bound becomes \(2(1+\delta)/((1-\delta)a)>2/a\), so momentum widens the range of stable learning rates.
However, the characteristic roots are complex when the discriminant \(c^2-4\delta<0\). Complex roots mean the iterates oscillate even while converging: the algorithm overshoots and corrects, cycling around the optimum before settling down. This explains why momentum can accelerate convergence in directions of persistent gradient but produces oscillatory transient behavior when the effective step size is aggressive.
4.11 References
Dauphin, Yann N., Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. 2014. “Identifying and Attacking the Saddle Point Problem in High-Dimensional Non-Convex Optimization.” In Advances in Neural Information Processing Systems. Vol. 27. Curran Associates.
Duchi, John, Elad Hazan, and Yoram Singer. 2011. “Adaptive Subgradient Methods for Online Learning and Stochastic Optimization.”Journal of Machine Learning Research 12: 2121–59.
Hamilton, James D. 1994. Time Series Analysis. Princeton, NJ: Princeton University Press.
Kingma, Diederik P., and Jimmy Ba. 2015. “Adam: A Method for Stochastic Optimization.” In International Conference on Learning Representations. https://arxiv.org/abs/1412.6980.
Loshchilov, Ilya, and Frank Hutter. 2019. “Decoupled Weight Decay Regularization.” In International Conference on Learning Representations. https://openreview.net/forum?id=Bkg6RiCqY7.
Nesterov, Yurii. 1983. “A Method of Solving a Convex Programming Problem with Convergence Rate \(O(1/k^2)\).”Soviet Mathematics Doklady 27 (2): 372–76.
Polyak, Boris T. 1964. “Some Methods of Speeding up the Convergence of Iteration Methods.”USSR Computational Mathematics and Mathematical Physics 4 (5): 1–17. https://doi.org/10.1016/0041-5553(64)90137-5.
Robbins, Herbert, and Sutton Monro. 1951. “A Stochastic Approximation Method.”Annals of Mathematical Statistics 22 (3): 400–407. https://doi.org/10.1214/aoms/1177729586.