Under active development. A stable version is expected in November 2026. Feedback is welcome by email or via GitHub issues.
Advanced Tree-Based Methods
13 Advanced Tree-Based Methods
13.1 Overview
The previous chapters treated trees, random forests, and gradient boosting mainly as tools for conditional-mean or conditional-event-probability prediction. In many econometric applications, that is not enough. A risk manager may need conditional quantiles of future losses, a central bank may care about the probability of extreme inflation outcomes, and an asset-pricing application may require a full predictive distribution rather than a point forecast.
This chapter extends tree-based methods in that direction. We focus on two ideas:
distributional and quantile random forests, which reuse random-forest neighborhoods to estimate conditional distributions nonparametrically (Meinshausen 2006)
NGBoost, which extends boosting to parametric predictive distributions and uses natural gradients to update distribution parameters (Duan et al. 2020)
The chapter remains predictive rather than structural. Generalized random forests (Athey, Tibshirani, and Wager 2019), honesty for causal forests, and local-linear forests are important related topics, but they are beyond the scope of this chapter.
13.2 Roadmap
We start from the standard random-forest weight representation and use it to diagnose what ordinary forests do and do not provide.
We then define distributional and quantile random forests through weighted empirical CDFs and leaf-neighbor outcomes.
Next we introduce NGBoost as a parametric distributional version of gradient boosting.
We explain the role of Fisher information, natural gradients, and constrained parameterizations.
We close with a comparison, summary, pitfalls, and exercises.
13.3 Standard Forests as Weighted Averages
A standard random forest predicts a conditional mean by averaging outcomes of training observations that frequently land in the same leaves as the forecast point. Let \(L_b(x)\) denote the terminal leaf reached by \(x\) in tree \(b\), and let \(N_b(x)\) be the number of training observations in that leaf. The forest prediction can be written as
This is a useful way to read a forest. The weights \(w_i(x)\) define a local neighborhood around \(x\), but the neighborhood is learned by recursive splits rather than fixed by Euclidean distance.
Why this matters
The weight view separates two ingredients:
the forest learns which training observations are local neighbors of \(x\)
the prediction rule decides what to do with the outcomes of those neighbors
A standard random forest uses those neighbors to estimate a conditional mean. A distributional forest uses the same neighbors to estimate a conditional distribution.
13.4 Limits of Standard Random Forests
The weighted-average view also makes the limits of ordinary forests clear.
Only a point prediction
A standard regression forest estimates something like \(\mathbb{E}[Y\mid X=x]\). It does not directly report tail probabilities, quantiles, skewness, or multimodality of \(Y\mid X=x\).
Constant local model
Inside each leaf, the local prediction is an average. This is simple and stable, but it can be inefficient when the relationship inside a neighborhood is locally smooth rather than locally constant.
Prediction, not causality
The forest neighborhood is chosen to improve prediction. A split or variable importance measure should not be interpreted as a treatment effect or structural parameter without an identification design.
Potential honesty problem
A split is honest when the data used to choose the split structure and the data used to estimate the leaf values are disjoint, so the observation that determines a split does not also contribute to that leaf’s prediction. The same observations are often used both to choose the tree structure and to compute leaf averages, violating honesty. That adaptivity can create bias in some settings because the prediction rule reuses data that helped select the splits.
13.5 Distributional and Quantile Random Forests
Distributional forests keep the forest neighborhood idea but change the object estimated from the neighbors. Instead of reporting only
This is a weighted empirical distribution of the training outcomes. Once we have \(\hat F(y\mid X=x)\), we can compute conditional medians, prediction intervals, lower-tail probabilities, and other distributional functionals.
Quantile random forests focus on conditional quantiles. For a probability level \(\alpha\in(0,1)\), the estimated conditional quantile is
An equivalent implementation view is to collect the training outcomes that share terminal leaves with \(x\) across the forest, keep duplicates when an observation is a neighbor in multiple trees, and compute empirical quantiles of that pooled neighbor sample.
Consistency of \(\hat F(y\mid X=x)\)
Consistency of the weighted empirical CDF \(\hat F(y\mid X=x)\) as an estimator of the true conditional CDF requires more than the bagging logic of Chapter 11. The honest-forest framework of Wager and Athey (2018) imposes (i) subsampling in place of bootstrap, (ii) honest split / leaf separation (the observation that determines the split must not also contribute to the leaf prediction), and (iii) smoothness of the conditional CDF in a neighborhood of \(x\). Off-the-shelf implementations that reuse RandomForestRegressor for QRF typically violate (i) and (ii). The resulting quantile estimates remain useful for prediction but should not be treated as having a formal pointwise consistency guarantee.
Question for Reflection
Why can two forests with the same conditional-mean prediction still give different conditional quantile estimates?
Suggested Answer
The conditional mean uses only a weighted average of neighboring outcomes. Conditional quantiles depend on the full weighted empirical distribution of those outcomes. Two neighbor distributions can have the same mean but different spread, skewness, or tail mass, so their quantiles can differ even when the mean prediction is identical.
13.6 Econometric Use and Limits of Distributional Forests
Distributional forests are attractive when heteroskedasticity or tail risk is central. Examples include volatility forecasting, downside return risk, firm default loss distributions, and macroeconomic fan charts. They can adapt prediction intervals to the covariates because the neighborhood around \(x\) changes with the forest partitions.
The main advantage is flexibility: the method is nonparametric in the conditional distribution and can represent skewness, fat tails, and multimodality through the empirical neighbor distribution. The main limitation is that the estimator is still local. If the relevant tail event is rare, the local neighborhood may contain little information about the tail. Like ordinary forests, distributional forests also need validation that respects dependence, publication lags, and forecast-origin information sets.
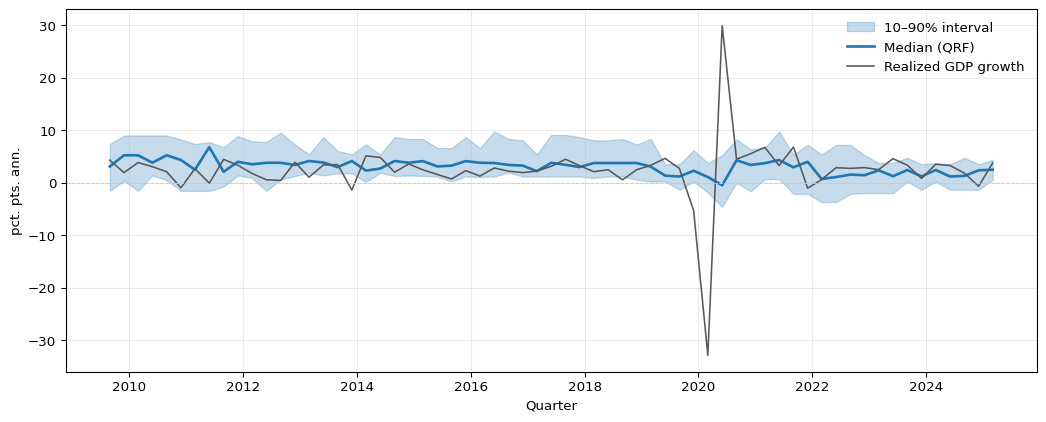
Figure 13.1 illustrates distributional forest forecasts on FRED-QD data. A quantile random forest is trained to predict annualized GDP growth in quarter \(t+1\) from five predictors dated quarter \(t\).1 In the test period, the forecast interval widens noticeably around the 2020 contraction and its aftermath, where elevated VIX and deteriorating macro conditions shift the forest neighborhood toward more dispersed training observations. The median prediction broadly tracks realized growth, but the interval width is not constant — it adapts to predictor values in a way that a parametric homoskedastic model would not.
Figure 13.1: Quantile random forest forecasts for one-step-ahead GDP growth (annualized log-difference of GDPC1) on the FRED-QD test period (last 25% of available quarters). The shaded band spans the conditional 10th to 90th percentile; the solid blue line is the conditional median; the gray line is realized GDP growth. Conditional quantiles are estimated via the weighted empirical distribution of training outcomes that share terminal leaves with each test observation, averaged across 200 trees.
13.7 NGBoost: Parametric Distributional Boosting
NGBoost takes a different route. Instead of estimating the conditional distribution nonparametrically from forest neighbors, it chooses a parametric family
\[
Y\mid X=x \sim P_{\theta(x)}
\]
and learns the parameter vector \(\theta(x)\) by boosting. For example, a Gaussian predictive distribution might use \(\theta(x)=(\mu(x),\sigma(x))\), while a positive target might use an exponential distribution with a rate parameter.
The training objective is usually the negative log-likelihood (NLL)
\[
\ell(\theta;y)=-\log p_\theta(y).
\]
This connects NGBoost to the distributional-network chapter and the predictive-distribution evaluation chapter: minimizing average NLL is the training analogue of optimizing the logarithmic score (see ?@sec-mini-log-score-kl).
Standard Boosting vs NGBoost
Standard squared-error boosting learns one scalar prediction function, typically a conditional mean. NGBoost learns one or more functions that parameterize a full predictive distribution. The price of this richer output is that the researcher must choose a distributional family and respect its parameter constraints.
13.8 Natural Gradients and Fisher Scaling
NGBoost’s defining choice is the natural gradient. In an ordinary gradient step, parameters are updated using the Euclidean gradient of the loss. For distribution parameters, this can be poorly scaled: a one-unit change in a mean parameter and a one-unit change in a scale parameter need not have comparable effects on the predictive density.
Let
\[
g_i
=
\nabla_\theta \ell(\theta(x_i);y_i)
\]
be the ordinary gradient for observation \(i\). The Fisher information matrix is
The natural gradient rescales the ordinary gradient:
\[
\tilde g_i
=
F(\theta(x_i))^{-1}g_i.
\]
NGBoost fits a weak learner, often a shallow tree, to these natural-gradient targets and then updates the predicted distribution parameters. The intuition is that the Fisher matrix measures the local curvature of the statistical model, so the natural gradient makes steps that are more comparable across parameters.
13.9 Parameterization and Update Choices
Distribution parameters often have constraints. A variance, standard deviation, rate, or scale parameter must be positive, and a probability must lie in \((0,1)\). NGBoost implementations therefore usually predict unconstrained functions and transform them into valid distribution parameters.
Examples:
predict \(\log \sigma(x)\) rather than \(\sigma(x)\)
use a softplus transformation \(\zeta(x)=\log(1+e^{x})\), which is smooth and strictly positive, for positive scale parameters
use a logistic transformation \(\sigma(x)=1/(1+e^{-x})\) for probabilities
For multi-parameter distributions, updates can be performed jointly or coordinate-wise. A joint update fits a multi-output learner to all components of the natural gradient at once. A coordinate update cycles through parameters, fitting one tree for the mean component, then one for the scale component, and so on. Coordinate updates can be easier to stabilize when the base learners are shallow.
13.10 QRF vs NGBoost
Distributional forests and NGBoost both produce conditional predictive distributions, but in opposite ways: distributional forests are nonparametric (the conditional law is the weighted empirical distribution of training outcomes in a forest neighborhood), while NGBoost is parametric (the conditional law belongs to a chosen family, and boosting iteratively fits its parameters).
Method
Distributional object
Main advantage
Main limitation
Quantile / distributional random forest
Weighted empirical CDF from forest neighbors
Nonparametric shape and adaptive intervals
Tail estimates can be noisy with few local tail observations
NGBoost
Parametric density \(P_{\theta(x)}\)
Smooth full predictive density and likelihood-based training
Sensitive to distributional misspecification
In econometric work, the choice depends on the forecasting object. If the goal is flexible local quantiles with few parametric assumptions, a distributional forest is natural. If the goal is a smooth parametric predictive density with likelihood-based training, NGBoost is more natural.
13.11 Summary
Key Takeaways
A standard random forest can be written as a weighted average of training outcomes, where the weights are determined by shared terminal leaves.
Distributional and quantile random forests use the same weights to estimate a weighted empirical conditional CDF rather than only a conditional mean.
Quantile random forests can produce conditional quantiles and prediction intervals without specifying a parametric distribution.
NGBoost learns parameters of a predictive distribution by minimizing a proper scoring rule such as negative log-likelihood.
Natural gradients rescale ordinary gradients by the Fisher information, which helps balance updates across distribution parameters.
Both approaches remain predictive tools; they do not solve identification or dependence-aware validation problems automatically.
Common Pitfalls
Treating a distributional forest as calibrated without checking out-of-sample distributional scores or probability integral transform (PIT) diagnostics (see ?@sec-eval-dist-pit).
Forgetting that tail quantiles require enough relevant tail observations in the forest neighborhood.
Interpreting forest weights, splits, or importance measures causally.
Choosing an NGBoost distributional family whose support or tail behavior is inconsistent with the outcome.
Updating constrained parameters directly instead of using log, softplus, or other transformations that enforce valid distributions.
Using random validation splits for time-series or panel forecasting targets with dependence or publication lags.
13.12 Exercises
Exercise 13.1: Quantile Random Forest Prediction
You trained a Quantile Random Forest with \(B=3\) trees to forecast a lower-tail outcome such as next-period portfolio returns. For a new test point \(x_{\text{new}}\), you collect all training outcomes \(Y_i\) that fall into the terminal leaf reached by \(x_{\text{new}}\) in each tree:
Tree 1 leaf: \(\{10,\,12,\,15\}\)
Tree 2 leaf: \(\{8,\,11,\,12\}\)
Tree 3 leaf: \(\{12,\,14,\,20\}\)
Questions:
What is the pooled neighbor sample for \(x_{\text{new}}\) when duplicates are kept?
Using the weight representation \[
w_i(x_{\text{new}})
=
\frac{1}{B}\sum_{b=1}^B \frac{1\{x_i \in L_b(x_{\text{new}})\}}{N_b(x_{\text{new}})},
\] derive the weight attached to each distinct outcome value in the pooled sample.
Construct the weighted empirical CDF \(\hat F(y \mid X=x_{\text{new}})\) and use \[
\hat q_\alpha(x_{\text{new}})=\inf\{y:\hat F(y\mid X=x_{\text{new}})\ge \alpha\}
\] to compute the predicted conditional median and conditional 25th percentile.
Explain why duplicates should not automatically be removed in this pooled-neighbor calculation.
Suppose this QRF is used to estimate a 10% lower-tail forecast for daily returns, but realized outcomes fall below the estimated 10% quantile much more often than 10% of the time. What does that suggest about the estimated lower tail?
Exam level. Parts 1-3 connect pooled neighbors to forest weights and weighted empirical quantiles, Part 4 checks the neighborhood interpretation, and Part 5 adds an econometric diagnostic about tail calibration.
Hint for Part 1
Pool the leaf outcomes from all trees, keep duplicates, and sort the result.
Hint for Part 2
Each tree contributes weight \(1/B = 1/3\), and each leaf has size 3. So one appearance of an outcome in one tree contributes weight \(1/9\).
Hint for Part 3
Build the cumulative weight on the sorted distinct outcomes. The quantile is the first value at which cumulative weight reaches or exceeds \(\alpha\).
Hint for Part 4
Ask what it means if the same training outcome shares a terminal leaf with \(x_{\text{new}}\) in more than one tree.
Hint for Part 5
If the realized exceedance rate is too high, the estimated lower quantile is not far enough into the lower tail.
Solution
Part 1: Neighbor set
Pooling gives
\[
\{10,12,15,8,11,12,12,14,20\}.
\]
Sorted, this is
\[
\{8,10,11,12,12,12,14,15,20\},
\]
with \(N=9\) total pooled neighbors.
Part 2: Forest weights
Each tree assigns weight \(1/3\) to its leaf, and each leaf contains three outcomes. So one appearance in one tree contributes
\[
\frac{1}{3}\cdot \frac{1}{3}=\frac{1}{9}.
\]
The distinct outcomes and their total weights are therefore
So the repeated appearance of \(12\) means it receives the largest forest weight.
Part 3: Weighted empirical CDF and quantiles
The weighted empirical CDF places mass on the sorted distinct outcomes as follows:
\(y\)
Weight
Cumulative weight
8
\(1/9\)
\(1/9\)
10
\(1/9\)
\(2/9\)
11
\(1/9\)
\(3/9\)
12
\(1/3\)
\(6/9\)
14
\(1/9\)
\(7/9\)
15
\(1/9\)
\(8/9\)
20
\(1/9\)
\(1\)
For the median, we need the first value where cumulative weight reaches at least \(0.5\). That happens at \(y=12\), so
\[
\hat q_{0.5}(x_{\text{new}})=12.
\]
For the 25th percentile, we need the first value where cumulative weight reaches at least \(0.25\). Since
\[
\frac{2}{9}<0.25\le \frac{3}{9},
\]
the conditional 25th percentile is
\[
\hat q_{0.25}(x_{\text{new}})=11.
\]
Part 4: Duplicates
Duplicates reflect forest weights. If an outcome appears as a neighbor in several trees, the forest has repeatedly placed that training observation in the same local neighborhood as \(x_{\text{new}}\). Removing duplicates would discard part of the weighting information.
Part 5: Tail calibration
If realized outcomes fall below the estimated 10% quantile more often than 10% of the time, the lower tail is too optimistic or too thin in the relevant region. In other words, the estimated 10% quantile is too high, so the forest is understating downside risk out of sample.
Exercise 13.2: NGBoost with Exponential Likelihood
Assume we model a positive target variable \(Y\) with a conditional Exponential distribution:
NGBoost can be used to learn the rate parameter function \(\lambda(x)\).
Questions:
Contrast NGBoost with standard gradient boosting under MSE and with Quantile Regression Forests.
Write the per-observation negative log-likelihood \(\ell(\lambda;y)\) and compute the ordinary gradient \(\partial \ell/\partial \lambda\).
The Fisher information for \(\lambda\) is \(F_{\lambda\lambda}=1/\lambda^2\). Compute the natural gradient \(g^{\text{nat}}_\lambda=F_{\lambda\lambda}^{-1}\partial \ell/\partial \lambda\).
For \(\lambda=0.4\) and \(y=3\), compute the ordinary gradient and the natural gradient for \(\lambda\).
Let \(\theta(x)=\log \lambda(x)\), so \(\lambda=e^\theta\). Compute \(\partial \ell/\partial \theta\) and explain why this parameterization is useful.
Note that the natural gradient is more important for multi-parameter densities, where it standardizes gradients across parameters.
Exam level. The exercise connects likelihood calculation, constrained parameters, and the natural-gradient idea in a one-parameter model.
Hint for Part 2
The negative log-likelihood is \(-\log f(y;\lambda)\). Use \(\log(ab)=\log a+\log b\).
Hint for Part 3
The natural gradient multiplies the ordinary gradient by \(F_{\lambda\lambda}^{-1}\).
Standard gradient boosting under MSE learns a scalar point prediction, typically the conditional mean, by fitting trees to residuals or negative gradients. Quantile Regression Forests estimate the conditional distribution nonparametrically by using forest neighbors and empirical quantiles. NGBoost specifies a parametric predictive family and learns its parameters by minimizing a proper scoring rule such as NLL, using natural gradients.
Part 2: NLL and ordinary gradient
The negative log-likelihood is
\[
\ell(\lambda;y)
=
-\log(\lambda e^{-\lambda y})
=
-\log\lambda+\lambda y.
\]
The log-rate parameterization is useful because it turns the constrained parameter \(\lambda>0\) into an unconstrained parameter \(\theta\in\mathbb{R}\). A tree booster can update \(\theta\) freely, and the transformation guarantees that the implied rate \(\lambda=e^\theta\) remains positive.
13.13 References
Athey, Susan, Julie Tibshirani, and Stefan Wager. 2019. “Generalized Random Forests.”Annals of Statistics 47 (2): 1148–78. https://doi.org/10.1214/18-AOS1709.
Duan, Tony, Anand Avati, Daisy Yi Ding, Khanh K. Thai, Sanjay Basu, Andrew Y. Ng, and Alejandro Schuler. 2020. “NGBoost: Natural Gradient Boosting for Probabilistic Prediction.” In Proceedings of the 37th International Conference on Machine Learning, 119:2690–700. Proceedings of Machine Learning Research.
Meinshausen, Nicolai. 2006. “Quantile Regression Forests.”Journal of Machine Learning Research 7: 983–99.
Wager, Stefan, and Susan Athey. 2018. “Estimation and Inference of Heterogeneous Treatment Effects Using Random Forests.”Journal of the American Statistical Association 113 (523): 1228–42. https://doi.org/10.1080/01621459.2017.1319839.
Footnotes
This is a pedagogical final-vintage FRED-QD example. A full real-time GDP forecasting evaluation would also need to account for release calendars and data revisions.↩︎